!pip install setfit datasets16 Method 2: SetFit
When working with limited labelled data1, traditional fine-tuning methods can be resource-intensive and less effective. SetFit is a framework that offers an efficient and prompt-free approach for few-shot text classification. It leverages sentence transformers and contrastive learning to achieve high accuracy with minimal data.
At a high level, the SetFit process involves:
- Model Selection: Choosing a pre-trained sentence transformer (e.g., paraphrase-mpnet-base-v2).
- Data Preparation: Formatting your labelled examples.
- Contrastive Fine-Tuning: Generating sentence pairs and fine-tuning the model using contrastive learning.
- Classifier Training: Training a classification head on the embeddings produced by the fine-tuned model.
- Evaluation: Assessing model performance on a validation and finally test sets.
SetFit is a method for fine-tuning Sentence Transformers for classification tasks with limited labelled data. It involves:
- Pre-trained Sentence Transformer: Starting with a model like SBERT (Sentence-BERT).
- Few-Shot Learning: Using a small number of labelled examples per class.
- Contrastive Learning: Fine-tuning the model using contrastive loss functions.
- Classification Head: Adding a simple classifier on top of the embeddings.
Benefits
- Data Efficiency: Achieves good performance with as few as 8 examples per class.
- Computationally Light: Fine-tunes quickly and requires less computational power.
- No Prompts Needed: Eliminates the need for hand-crafted prompts.
Limitations
- Performance ceiling: May not match the performance of models fine-tuned on large datasets
- Dependence of pre-trained model quality: The quality of embeddings is tied to the pre-trained model used.
When to Use SetFit?
- If you have a small amount of labelled data.
- For quick prototyping and iterative development (if time allows, give SetFit a go first and if it looks promising then it’s worth labelling up more data to perform vanilla fine-tuning).
16.1 How to fine-tune a model with SetFit?
Let’s dive into fine-tuning a model using SetFit. This section will get you started quickly. Feel free to run the code, experiment, and learn by doing. After this walkthrough, we’ll provide a more detailed explanation of each step.
Start by installing the required packages/modules…
… before loading in our dataset. For this example, we’ll use the sst2 (Stanford Sentiment Treebank) dataset, which is great for sentiment analysis as it is single sentences extracted from movie reviews that have been annotated as either positive or negative.
from datasets import load_dataset
dataset = load_dataset("SetFit/sst2")Prepare the data
Now we have loaded in the data, let’s prepare it for the SetFit framework. The benefit of SetFit is being able to perform model fine-tuning with very few labelled data. As such, we will load in data from the SetFit library, but will sample it so we only keep 8 (yes 8!) instances of each label for fine-tuning to simulate a few-shot learning scenario. Note the dataset provided is already split up into training, testing, and validation sets (and it is the training set we will be sampling). The testing set is left unaffected for better evaluation.
# Use 8 examples per class for training
train_dataset = sample_dataset(dataset["train"], label_column="label", num_samples=8)
# Obtain the validation and test datasets
validation_dataset = dataset["validation"]
test_dataset = dataset["test"]Loading a Pre-trained SetFit Model
Then initialise a SetFit model using a Sentence Transformer model of our choice. For this example we will use BAAI/bge-small-en-v1.5:
from setfit import SetFitModel
model = SetFitModel.from_pretrained("BAAI/bge-small-en-v1.5",
labels=["negative", "positive"])Now we prepare TrainingArguments for training- the most frequently used arguments (hyperparamters) are num_epochs and max_steps which affect the number of total training steps. We then initialise the Trainer and perform the training
from setfit import TrainingArguments
args = TrainingArguments(
batch_size=32,
num_epochs=10,
)
from setfit import Trainer
trainer = Trainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=validation_dataset,
metric="accuracy",
column_mapping={"sentence": "text", "label": "label"}
)
trainer.train()16.2 Evaluating the Model
After training, evaluate the model on the validation dataset.
metrics = trainer.evaluate()
print(metrics)Finally once we are happy with model performance based on the validation data, we can evaluate using the testing dataset.
trainer.evaluate(test_dataset)Now we can save (or load) the model as needed
model.save_pretrained("setfit-bge-small-v1.5-sst-8-shot") # Save to a local directory
model = SetFitModel.from_pretrained("setfit-bge-small-v1.5-sst-8-shot") # Load from a local directoryOnce a SetFit model has been trained, it can be used for inference straight away using SetFitModel.predict()
texts = [
"I love this product! It's fantastic.",
"Terrible customer service. Very disappointed.",
]
predictions = trainer.model.predict(texts)
print(predictions)Congratulations! You’ve fine-tuned a SetFit model for sentiment analysis. Feel free to tweak the code, try different datasets, and explore further.
16.3 Detailed overview
SetFit is a few-shot learning method that fine-tunes sentence embeddings to match the desired classification task. It uses contrastive learning to train embeddings such that examples of the same class are pulled closer in the embedding space, while examples from different classes are pushed apart. After fine-tuning an embedding model (sentence transformer), a lightweight classifier like logistic regression is trained on these embeddings, allowing for efficient and accurate classification with minimal labeled data.
What is Contrastive Learning?
The goal of contrastive learning is to learn an embedding space where similar pairs of samples are positioned close together, while dissimilar pairs are kept far apart.
Put simply, the model learns by comparing examples: it is trained to pull similar items closer in the representation space and push dissimilar items further apart.
How is this achieved?
Note the below is directly copied from the SetFit documentation. It is so succinctly written that trying to rewrite it would not do it justice.
Every SetFit model consists of two parts: a sentence transformer embedding model (the body) and a classifier (the head). These two parts are trained in two separate phases: the embedding finetuning phase and the classifier training phase. This conceptual guide will elaborate on the intuition between these phases, and why SetFit works so well.
Embedding finetuning phase
The first phase has one primary goal: finetune a sentence transformer embedding model to produce useful embeddings for our classification task. The Hugging Face Hub already has thousands of sentence transformer available, many of which have been trained to very accurately group the embeddings of texts with similar semantic meaning.
However, models that are good at Semantic Textual Similarity (STS) are not necessarily immediately good at our classification task. For example, according to an embedding model, the sentence of 1) “He biked to work.” will be much more similar to 2) “He drove his car to work.” than to 3) “Peter decided to take the bicycle to the beach party!”. But if our classification task involves classifying texts into transportation modes, then we want our embedding model to place sentences 1 and 3 closely together, and 2 further away.
To do so, we can finetune the chosen sentence transformer embedding model. The goal here is to nudge the model to use its pretrained knowledge in a different way that better aligns with our classification task, rather than making the completely forget what it has learned.
For finetuning, SetFit uses contrastive learning. This training approach involves creating positive and negative pairs of sentences. A sentence pair will be positive if both of the sentences are of the same class, and negative otherwise. For example, in the case of binary “positive”-“negative” sentiment analysis, (“The movie was awesome”, “I loved it”) is a positive pair, and (“The movie was awesome”, “It was quite disappointing”) is a negative pair.
During training, the embedding model receives these pairs, and will convert the sentences to embeddings. If the pair is positive, then it will pull on the model weights such that the text embeddings will be more similar, and vice versa for a negative pair. Through this approach, sentences with the same label will be embedded more similarly, and sentences with different labels less similarly.
Conveniently, this contrastive learning works with pairs rather than individual samples, and we can create plenty of unique pairs from just a few samples. For example, given 8 positive sentences and 8 negative sentences, we can create 28 positive pairs and 64 negative pairs for 92 unique training pairs. This grows exponentially to the number of sentences and classes, and that is why SetFit can train with just a few examples and still correctly finetune the sentence transformer embedding model. However, we should still be wary of overfitting.
Classifier training phase
Once the sentence transformer embedding model has been finetuned for our task at hand, we can start training the classifier. This phase has one primary goal: create a good mapping from the sentence transformer embeddings to the classes.
Unlike with the first phase, training the classifier is done from scratch and using the labelled samples directly, rather than using pairs. By default, the classifier is a simple logistic regression classifier from scikit-learn. First, all training sentences are fed through the now-finetuned sentence transformer embedding model, and then the sentence embeddings and labels are used to fit the logistic regression classifier. The result is a strong and efficient classifier.
Using these two parts, SetFit models are efficient, performant and easy to train, even on CPU-only devices.
Visual example
For example, if we naively used an “untrained” transformer model to embed data it may look like this in 2D:
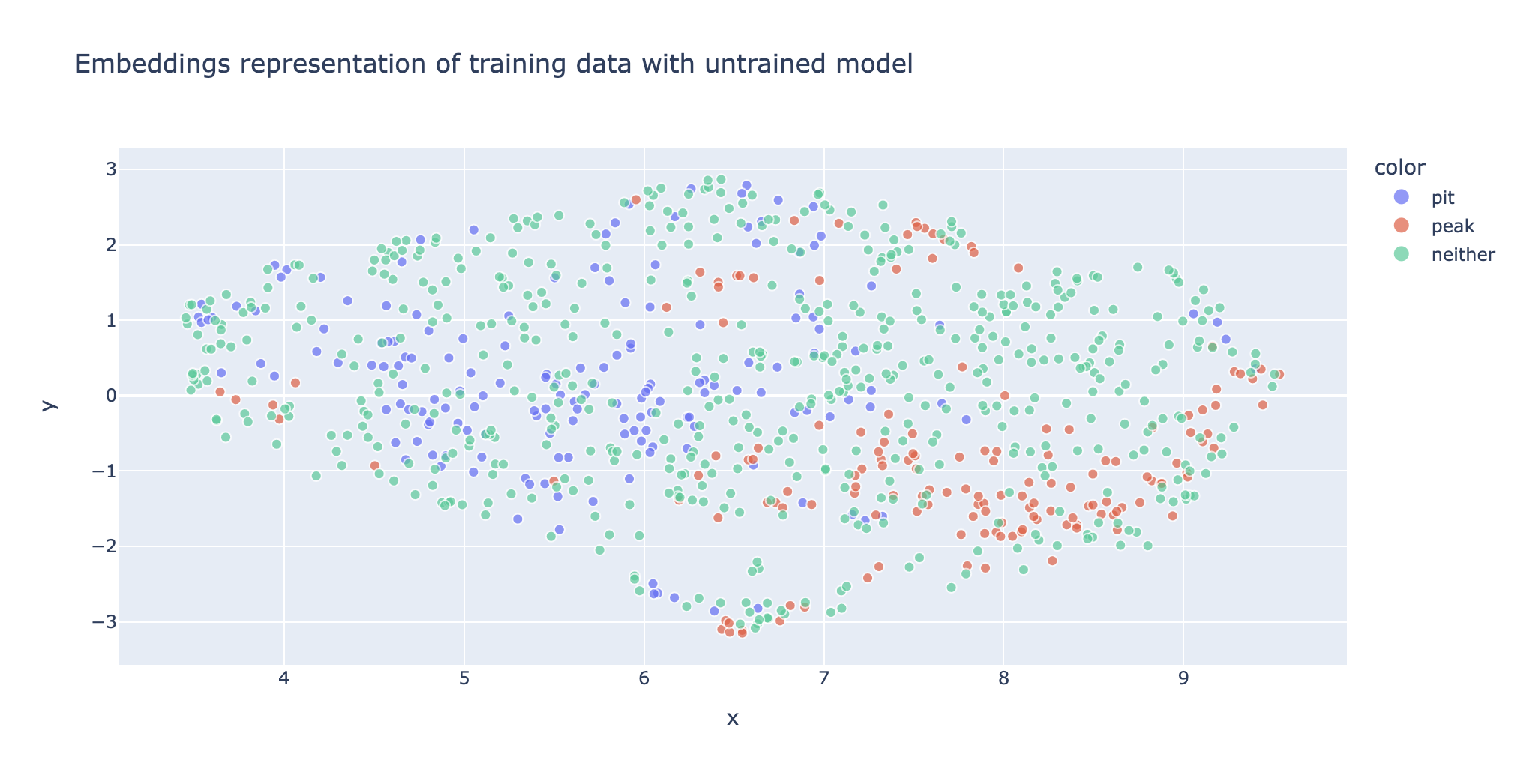
However after fine-tuning the embedding model through contrastive learning, we force similar posts (similar via our classification definition) to be nearer each other, we end up with the below:
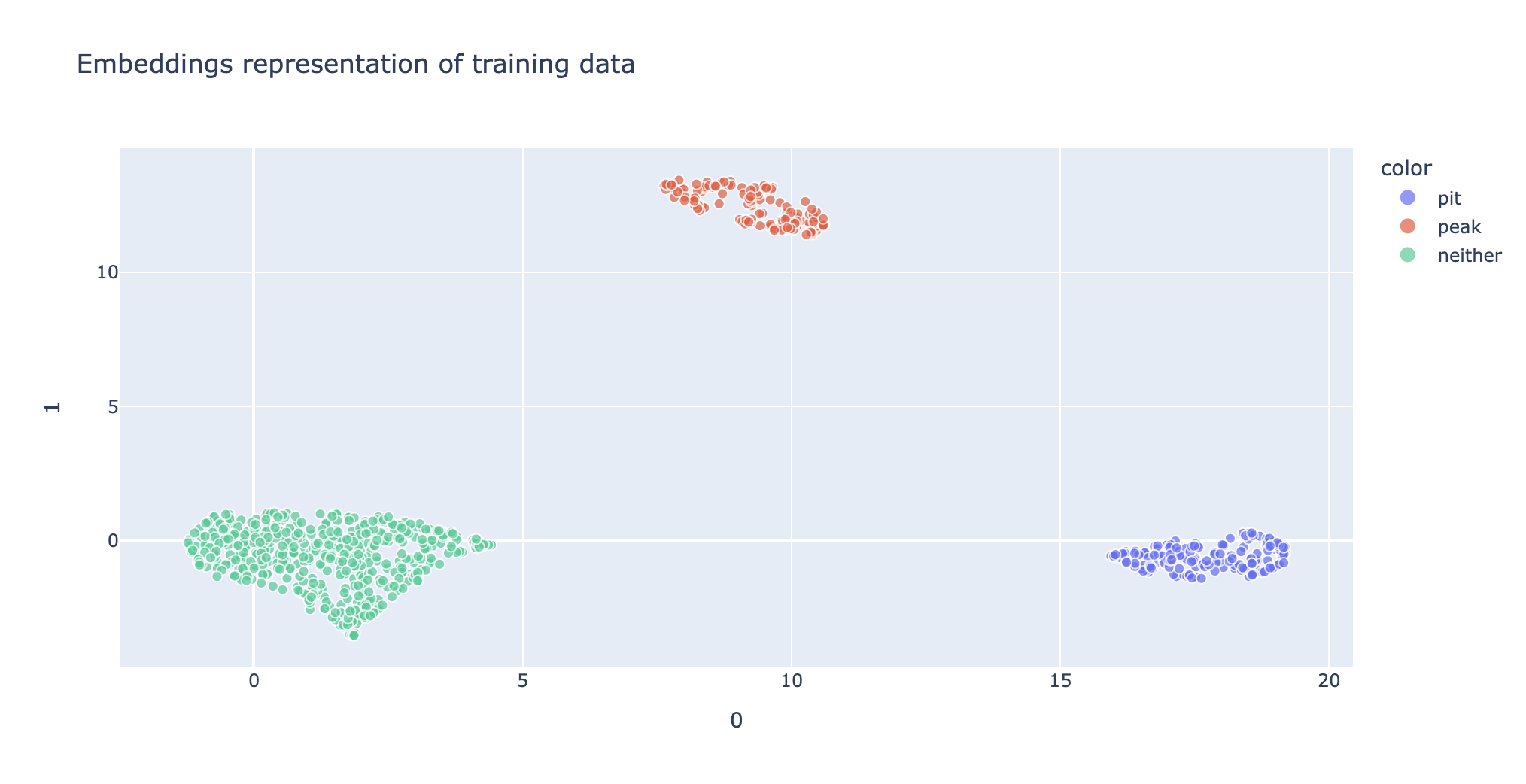
To get the most out of SetFit, I am a firm believer in being able to conceptualise what is going on behind the scenes. The SetFit documentation on the Hugging Face website is extremely good, and I think the “Conceptual Guides” pages on SetFit- what is written above and Sampling Strategies are absolute gold dust, and really must be read and understood to get a proper appreciate of SetFit.
Okay, now let’s dive deeper into each step.
Setting Up the Environment
Despite SetFit being lightweight, we still recommend you running it in a cloud environment like Google Colab to access the GPUs
As such, make sure you are connected to a GPU, we recommend T4 as it’s a good balance between speed and cost.
How do I do this?
To use a GPU in Colab, go to Runtime >Change runtime type and select a GPU under the hardware accelerator option
Install the required packages and modules
%%capture
# Install necessary packages
!pip install setfit datasets evaluate
# Imports
from datasets import load_dataset
from setfit import SetFitModel, Trainer, TrainingArgumentsLoad in the data
In the example above, we loaded in data that was already saved on the Hugging Face Hub and within the Hugging Face datasets library. However, we can also load in our own data that we have as a .csv file:
dataset = load_dataset('csv', data_files = path/to/csv)By using load_dataset, the dataframe should be read into your environment and be converted into a dataset dictionary (DatasetDict). You can inspect it by running the following command:
datasetThis will output something like:
DatasetDict({
train: Dataset({
features: ['universal_message_id', 'text', 'label'],
num_rows: 100
})
})You might notice that this looks slightly different from when we loaded the tweet-eval dataset earlier. In the tweet-eval dataset, the DatasetDict included splits for train, validation, and test. However, in our custom dataset, we only have a train split. This is because we haven’t explicitly created additional splits like validation or test, so all our data currently resides under the train key.
There are two ways we can approach this, we can either split up our dataset using train_test_split (which splits into random train and test subsets) or do splitting outside of python (say in R) and read in the already split datasets individually.
train_test_splitmethod:
This method requires you to first split the data into training and testing data, before then further splitting the training data into training and validation. Because of this some maths is required to workout the split proportions.
# Load your dataset (or create one)
dataset = load_dataset('csv', data_files=path/to/csv)
# Split dataset into train (70%) and test+validation (30%)
train_test_split = dataset['train'].train_test_split(test_size=0.3, seed=42)
# Split the remaining 30% into validation (15%) and test (15%)
validation_test_split = train_test_split['test'].train_test_split(test_size=0.5, seed=42)
train_dataset = train_test_split['train'] # 70% of data
validation_dataset = validation_test_split['train'] # 15% of data
test_dataset = validation_test_split['test'] # 15% of data- External splitting:
If you have split up the dataset into train, validation, and test splits already, we can read these in individually.
train_dataset = load_dataset('csv', data_files = path/to/csv)
validation_dataset = load_dataset('csv', data_files = path/to/csv)
test_dataset = load_dataset('csv', data_files = path/to/csv)Whichever approach you prefer, you can then bring the individual splits together into a single DatasetDict if needed.
complete_dataset = DatasetDict({
'train': train_dataset['train'],
'test': validation_dataset['train'],
'validation': test_dataset['train']
})Note that by default the dictionary key when you load in a dataset this way is train, which is why for each of train_dataset, validation_dataset and test_dataset are subset by ['train'].
Now is a good time to verify the datasets we have read in
# Verify the datasets
print("Train set:")
print(complete_dataset['train'])
print("Validation set:")
print(complete_dataset['validation'])
print("Test set:")
print(complete_dataset['test'])For the purposes of this more detailed tutorial, let’s again read in the sst2 dataset that we will work on:
dataset = load_dataset("SetFit/sst2"")
What about Tokenization?
With SetFit, the tokenization step is abstracted away within the SetFitTrainer class- so unlike Vanilla fine-tuning using the Trainer API we do not need to explicitly create a tokenizer class. Neat!
Loading the SetFit Model
We load a pre-trained model that is suitable for SetFit:
model = SetFitModel.from_pretrained("BAAI/bge-small-en-v1.5",
labels=["negative", "positive"])SetFitModel is a wrapper that combines a pre-trained body from sentence-transformers (i.e. the embedding layer) with a classification head (such as a Logistic Regression model).
Define metrics for evaluation
Evaluating a fine-tuned model often requires more than just accuracy. We also need metrics like precision, recall, and F1-score to understand how well the model handles different classes.
Please read the corresponding section in the handbook on Model Evaluation for more information on the theory and rationale behind these metrics, and when to chose one over the other.
Unlike the example above where we only evaluate using accuracy and loss, we need to define a function (which we will call compute_metrics()) that will enable the calculation of the necessary evaluation metrics. The code below provides per-class metrics and a weighted F1-score (which is useful for handling imbalanced datasets which we often obtain)
from sklearn.metrics import f1_score, precision_recall_fscore_support, accuracy_score
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
# Calculate precision, recall, and f1 for each label
precision, recall, f1, _ = precision_recall_fscore_support(labels, predictions, average=None, labels=[0, 1, 2])
# Calculate accuracy
accuracy = accuracy_score(labels, predictions)
# Calculate weighted and macro f1 scores
f1_weighted = f1_score(labels, predictions, average='weighted')
f1_macro = f1_score(labels, predictions, average='macro')
# Prepare the metrics dictionary
metrics = {
'accuracy': accuracy,
'f1_weighted': f1_weighted,
'f1_macro': f1_macro
}
class_names = ["negative", "neutral", "positive"]
for i, label in enumerate(class_names):
metrics[f'precision_{label}'] = precision[i]
metrics[f'recall_{label}'] = recall[i]
metrics[f'f1_{label}'] = f1[i]
return metricsTraining arguments
We set up the training arguments by creating a TrainingArguments class which contains all the hyperparameters you can tune as well:
args = TrainingArguments(
batch_size=16,
num_epochs=4,
eval_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
)Let’s go through each of these hyperparameters/arguments step by step, explaining what they are and how we can choose an appropriate value (where relevant)
batch_size: Sets the batch size. Sets the batch size, which is the number of samples processed before the model updates its weights during training. Larger batch sizes (e.g., 32, 64) lead to faster training but require more memory (RAM) and may lead to poorer model performance at generalising over unseen data. Smaller batch sizes (e.g. 8, 16) are slower but can help when memory is limited or for more stable training, however if it is too small the gradient estimation will be noisy and not converge. In our use cases 16 or 32 tends to work fine.num_epochs: Specifies the number of complete passes through the training dataset (an epoch). We find that fewer epochs (1-3) are suitable for fine-tuning when you’re only adjusting the final classification head, or if the model is large and already well-trained. More epochs (5-10) may be needed when we’re training with less data or starting with a less well-trained pre-trained model. We can implement “early stopping” so that if the model starts to drop in performance after a certain number of epochs, training halts to avoid overfitting.eval_strategy: Specifies when to run evaluation (validation) on the dataset during training. The values this hyperparameter can take areepoch(runs evaluation at the end of each epoch- common for most training tasks),steps(runs evaluation at a set number of steps, which is sometimes useful for longer training runs or when training for many epochs), orno(don’t evaluate- do not chose this!). We find thatepochis usually sufficient, but recommend tryingstepstoo if you’d like more control over evaluation visualisations.save_strategy: Specifies when to save the model checkpoint. Similar toeval_strategythe argument takesepoch(saves a model checkpoint at the end of every epoch- which is ideal for most fine-tuning tasks) orsteps(saves checkpoints every set number of steps, useful for longer training runs).load_best_model_at_end: Automatically loads the best model (based on the evaluation metric) after training completes. We would have this astrue.
trainer = Trainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
metric=compute_metrics,
column_mapping={"masked_context": "text", "label": "label"} # Map dataset columns to text/label expected by trainer
)Understanding the Parameters:
loss_class: The loss function to use. CosineSimilarityLoss works well for similarity tasks. metric: The evaluation metric. Here, we use accuracy. batch_size: Number of samples per batch during training. num_iterations: Controls how many text pairs are generated for contrastive learning. num_epochs: Number of times to iterate over the generated pairs.
Training the Model
Start the fine-tuning process.
trainer.train()What Happens During Training:
Pair Generation: Generates pairs of sentences that are similar or dissimilar.
Contrastive Learning: Fine-tunes the model to bring similar sentences closer in the embedding space and push dissimilar ones apart.
Classifier Training: Trains a classification head on the embeddings.
Evaluating the Model
Assess the model’s performance on the validation dataset.
metrics = trainer.evaluate()
metricsFinally once we are happy with model performance based on the validation data, we can evaluate using the testing dataset.
trainer.evaluate(test_dataset)16.4 Hyperparameter Optimisation
Because of the speed we can train SetFit models, they are suitable for hyperparameter optimisation to help select the best hyperparameters.
The hyperparameter optimisation section in the SetFit documentation goes through this in great detail, outlining what is required to do this.
Our advice would be:
To only do this as a final step, a cherry on top if you will. The improvements from hyperparameter optimisation will not improve a model built on poor data quality, and should really only be used to eke out some final extra percentage points in model performance.
Focus on
num_epochs,max_steps, andbody_learning_rateas the most important hyperparameters for the contrastive learning process.
16.5 Extras
There are many additional features of SetFit to explore, from multilabel classification to Aspect-Based Sentiment Analysis (ABSA). Since this framework is constantly evolving, it’s impossible to cover all potential implementations within this handbook. Therefore, we recommend regularly checking online resources and experimenting with different facets of SetFit as needed. You can find well-written guidance on the SetFit website. With experience, you’ll see how the knowledge, understanding, and skills developed through fine-tuning with Hugging Face can be applied across different approaches, including SetFit and traditional fine-tuning.
See the page on data labelling for our advice on knowing when you have limited data - rule of thumb here is < 100 posts per class↩︎