22 Package Development
One of the beautiful things about Data Science at SAMY is that you get to choose your path between research, development, or a hybrid. If you’re reading this, you’ve probably decided that you want to explore some development - what better way to start than building your own package?
For a high-level overview of our existing packages, refer to the our packages document.
We build packages because they are convenient ways to share our code & data and democratise access to our tools & workflows - besides, that Google Doc of functions is getting heavy, and copying & pasting code from project to project is getting tiresome. Eventually you’ll want the familiar library() syntax.
Historically our packages have been built in R for two key reasons:
- The profile/experience of people in the team
- The ecosystem for building packages is well-maintained and documented
In recent times we have moved to more of a hybrid approach between R & Python - the former we find to be considerably more easy to use for data wrangling and visualisation, and the latter for modelling and anything to do with LLMs. Internal development for Python has lagged behind R, but we expect this to change over time as we seek to be tool agnostic and focus on the right tool for the job at hand.
Reticulate is an R package that allows us to import Python packages and functions in R. Currently this is a one-way street - we can’t use reticulate to import R functions and packages. This has impacted our decision in the past, e.g. with BertopicR. We envisioned Insight Analysts using BertopicR as a drop-in or replacement for topic modelling with SegmentR. Weighing up the additional difficulty in development vs the time and resource necessary for Analysts to learn Python as well as R, we opted for reticulate.
Using reticulate requires managing Python environments from R, this leads to difficulties of its own.
23 R
Here we’ll look at how to get off the ground in R using the R package stack - {usethis}, {pkgdown}, {devtools}, {testthat} and {roxygen2}.
23.1 Building your own package
The (nearly) DIY way:
This check-list should get you most of the way there, but it’s always possible that we’ve forgotten something or there has been a disturbance in the force a change in the package ecosystem. When this happens, open up an issue or submit a PR and help the next person who comes along.
mkdir ~/git_repos cd ~/git_repos git clone 'repo.url'
Your package will now have a DESCRIPTION file, add external packages your package requires to Imports. Add additional packages used in vignettes to Suggests. - But be careful, it’s generally not advisable to use packages just for vignettes!
You can use the usethis::use_latest_dependencies() to add recent versions to your packages, but beware this can be restrictive. Ideally you would add the minimum package version necessary to run your code.
The Easy Way (Tidy functions) Read through the usethis-setup guide and then use the usethis::create_tidy_package() to create a package with some guardrails.
The usethis::create_tidy_package() function is a helpful abstraction, but it will be better for your long-term development if you know how to do this stuff without the abstraction. That way, when you need to fix something, or do something slightly different than the prescribed way, you’ll have a better chance of success.
Want to go deeper? Check out the R Packages Book, we recommend skimming first and then using it as a reference manual.
23.2 Development workflow
Once you’ve built the package there are some things you will want to do regularly to ensure your package stays in good shape. This is by no means an exhaustive list - be sure to add your tips & tricks as you amass them.

23.3 Contributing to existing packages
Vignettes are long-form guides that provide in-depth documentation for your package. They go beyond the basic function documentation and explain how to use the package to solve specific problems, often with detailed examples and code. Vignettes showcase your package’s full range of capabilities and help users understand how to effectively utilise its features
Pull request when ready.
Code
Generally code should sit in the R/ folder, you can choose between a script per function or use scripts as modules, where a module is a particular use case, or logical unit. Historically we sided on the former, but as a package grows it can become difficult to manage/navigate, and there can be a decoupling of logic. Ultimately this is a matter of taste in R.
Exercises - code
You may need to consult external resources to answer the exercises, we’ve tried to provide links to help you along the way, but we encourage you to embrace the joy of discovery and find relevant sources/fill in the gaps where necessary!
- What are the practical differences between
.gitignoreand.Rbuildignore?
- What objects should go in
.gitignorebut not.Rbuildignore, and vice versa?
- What does the DESCRIPTION file do?
- Write your own description for each of the following packages, detailing what they are for where they sit in the R package stack:
Tests
In a perfect world, every
dogimplementation detail would have ahometest and everyhometest would have an implementation detail.
There is a balance to be struck between testing absolutely everything and testing what needs to be tested. Before we get into the finer details, let’s establish why we’re writing tests in the first place. The first reason for writing tests is to help you write software that works. The second reason is to help you do this fast, and with confidence.
Testing is not to prove that your code has no bugs, or cannot have any bugs in the future. Whenever you do find a bug, or someone reports one, write a test as you fix the issue.
For more information and another opinion, check out the R Packages testing section, and the Testing document
Don’t let testing paralyse your development process, they’re there to help not hinder. As a rule-of-thumb, if your tests for a function are more complex than your function, you’ve gone too far.
Documentation
We use {roxygen2} tags to document our functions. Visit the documenting functions article for a primer.
Using the roxygen2 skeleton promotes consistent documentation, check out a function’s help page (e.g. ?ParseR::count_ngram) to see how rendered documentation looks - do this regularly with your own functions.
We tend to find our documentation could always be better, more complete. You can’t hope to cover everything a user could do with your function, but make sure it’s clear from the documentation what your function is for and what its primary uses are.
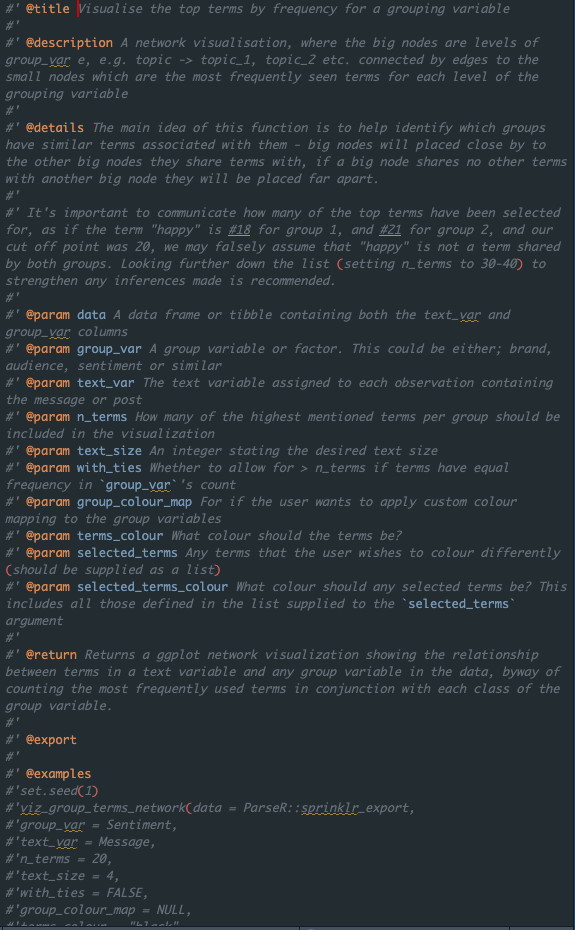
Most people will scroll straight past the @description and @details and go directly to your code examples.
Guidelines for commonly-used Roxygen tags
| Tag | Description |
|---|---|
| @title | One-line description of what your function does |
| @description | A paragraph elaborating on your title |
| @details | A more detailed description of the function e.g. explaining how its arguments interact, or other key implementation details. |
| @param | A description of the function’s parameters |
| @return | A description of the function’s return value |
| @examples | Examples of how to use the function |
| @export | Whether the function is exported or not |
Exercises - Documentation
- What is the title of {dplyr}’s
mutate()function? - @examples must be self-contained, create an example that is not self-contained, and one that is.
- Which package(s) (any programming language) stick out in your mind as being well-documented and easy to use, what did the creators do well?
- Audit SAMY’s R packages, find a function with sub-par documentation and upgrade it. Then fire in a Pull Request!
Data
You’re probably going to need some package-level data for your @examples or your vignettes. Before going off and finding or creating a new data set:
- Check whether you can demonstrate what you need with existing datasets - call
data()in your console - Make sure the dataset you have chosen comes from a package your package explicitly Imports or Suggests
If you still can’t find the right dataset, create one!
- Load the dataset into memory
- Call
usethis::use_data(dataset_variable_name) - Document the columns
If you choose this route, some interesting problems may lie in wait. Skip to Exercises 1.
To go deeper view the R Packages Dataset Section
Datasets from the {datasets} package come with base R
Exercises - Data
- Why might you add your data artefacts to
.Rbuildignoreor.gitignore? - Which package does the
diamondsdataset ship with?
You’re probably going to need some data… existing data… adding new usethis::use_data() usethis::use_data_raw()
Website
pkgdown .nojekyll
Exercises - Website
- Explain in your own words what .nojekyll is for.
- Where should it be placed in your package?
- What problems arise when you don’t have one?
24 Python
This document is very much a work in progress, key steps may be missing.
24.1 Folder Setup
The first step in creating a Python package is setting up the project structure. Create a new directory for your project and organize it with the following subdirectories and files:
Create a directory for your package and place an empty init.py file inside it. If your package has sub-packages or modules, create additional directories for them and place init.py files in each directory. Import your package or its modules in your Python scripts using the import statement or the from package import module syntax.
24.2 Git - Terminal
To set up a Git repository for your Python package from the terminal, follow these steps:
Open your terminal and navigate to the root directory of your Python package using the cd command. For example:
cd /path/to/your/packageInitialize a new Git repository by running the git init command:
git initAdd all the files in your package directory to the Git staging area using the git add command:
git add .Create an initial commit to save the current state of your package by running the git commit command with a meaningful commit message:
git commit -m "Initial commit"Add the remote repository URL to your local Git repository using the git remote add command:
git remote add origin <repo_url>Push your local commits to the remote repository using the git push command:
git push -u origin main
24.3 Vignettes
24.4 Tests
There are multiple viable frameworks, but for simplicity we recommend Pytest which functions quite similarly to {testthat}.
Pytest has great docs, work through the how-to guides to get up to speed.
25 Continuous Integration/Continuous Deployment
R templates etc. from RStudio Python templates