./example_folder
├── code
│ └── analysis.Rmd
└── data
├── clean_data.csv
└── raw_data.csv24 Coding best practices
First, make sure you’ve read the the Project Management document for general tips on setting up an RStudio project and working with file paths.
Note
To avoid being cumbersome, we’ll use ‘notebook’ to refer to the set of interactive software in which data science usually takes place. They’ll tend to end with one of the following extensions: .md, .Rmd, .qmd, or .ipynb.
24.1 Why are we here?
At SAMY, code is the language of both our research and our development, so it pays to invest in your coding abilities. There are many great (and many terrible) resources on learning how to code. This document will focus on practical tips on how to structure your code to reduce cognitive strain and do the best work you can.
Let’s be clear about what coding is: coding is thinking not typing, so good coding is simply good thinking and arranging our code well will help us to think better.
24.2 Reproducible Analyses
Above everything else, notebooks must be reproducible. What do we mean by reproducible? You and your collaborators should be able to get back to any place in your analysis simply by executing code in the order it occurs in your scripts and notebooks. Hopefully the truth of this statement is self-evident. But if that’s the case, why are we talking about it?
For some projects you’ll get away with a folder structure which looks something like this:
However, in weeks-long or even months-long research projects, if you’re not careful your project will quickly spiral out of control (see the lovely surprise below for a tame example), your R Environment will begin to store many variables, and you’ll begin to pass data objects around between scripts and markdowns in an unstructured way, e.g. you’ll reference a variable created inside ‘wrangling.Rmd’ inside the ‘colab_cleaning.Rmd’, such that colab_cleaning.Rmd becomes unreproducible.
A lovely surprise
./example_folder_complex
├── code
│ ├── colab_cleaning.Rmd
│ ├── edited_functions.R
│ ├── images
│ │ └── outline_image.png
│ ├── initial_analysis.Rmd
│ ├── quick_functions.R
│ ├── topic_modelling.Rmd
│ └── wrangling.Rmd
└── data
├── clean
│ ├── all_data_clean.csv
│ ├── all_data_clean_two.csv
│ ├── all_data_cleaner.csv
│ ├── data_topics_clean.csv
│ └── data_topics_newest.csv
└── raw
├── sprinklr_export_1.xlsx
├── sprinklr_export_10.xlsx
├── sprinklr_export_11.xlsx
├── sprinklr_export_12.xlsx
├── sprinklr_export_13.xlsx
├── sprinklr_export_14.xlsx
├── sprinklr_export_15.xlsx
├── sprinklr_export_16.xlsx
├── sprinklr_export_17.xlsx
├── sprinklr_export_18.xlsx
├── sprinklr_export_19.xlsx
├── sprinklr_export_2.xlsx
├── sprinklr_export_20.xlsx
├── sprinklr_export_21.xlsx
├── sprinklr_export_22.xlsx
├── sprinklr_export_23.xlsx
├── sprinklr_export_24.xlsx
├── sprinklr_export_25.xlsx
├── sprinklr_export_26.xlsx
├── sprinklr_export_27.xlsx
├── sprinklr_export_28.xlsx
├── sprinklr_export_29.xlsx
├── sprinklr_export_3.xlsx
├── sprinklr_export_30.xlsx
├── sprinklr_export_4.xlsx
├── sprinklr_export_5.xlsx
├── sprinklr_export_6.xlsx
├── sprinklr_export_7.xlsx
├── sprinklr_export_8.xlsx
└── sprinklr_export_9.xlsxLiterate Programming
“a script, notebook, or computational document that contains an explanation of the program logic in a natural language (e.g. English or Mandarin), interspersed with snippets of macros and source code, which can be compiled and rerun. You can think of it as an executable paper!”
Notebooks have become the de factor vehicles for Literate Programming and reproducible research. They allow you to couple your code, data, visualisations, interpretations and analysis. You can and should use the knit/render buttons regularly (found in the RStudio IDE) to keep track of whether your code is reproducible or not - follow the error messages to ensure reproducibility.
- [ ]
- [ ]
24.3 On flow and focus
Most of us cannot do our best work on the most difficult challenges for 8 hours per day. In fact, conservative estimates suggest we have 2-3 hours per day, or 4 hours on a good day, where we can work at maximum productivity on challenging tasks. Knowing that about ourselves, we should proactively introduce periods of high and low intensity to our days.
In periods of high intensity we’ll be problem solving - inspecting our data, selecting cleaning steps, running small scale experiments on our data: ‘What happens if I…’ and recording and interpreting the results. When the task is at the correct difficulty, you’ll naturally fall into a flow state. Try your best to prevent interruptions during this time. Protect your focus - don’t check your work emails, turn Slack off etc.
Whilst these high-intensity periods are rewarding and hyper-productive, at the other end there is often a messy notebook or some questionable coding practices. Allocate time each and every day to revisit the code, add supporting comments, write assertions and tests, rename variables to be more descriptive, tidy up unused data artefacts, study your visualisations to understand what the data can really tell you etc. or anything else you can do to let your brain rest, recharge and come back stronger tomorrow. You’ll sometimes feel like you don’t have time to do these things, but it’s quite the opposite - you don’t have time not to do them.
24.4 On managing complexity
“…let’s think of code complexity as how difficult code is to reason about and work with.”
There are many heuristics for measuring code complexity, the most basic being ‘lines of code’ which is closely linked to ‘vertical complexity’ - the more code we have the longer our scripts and markdowns will be, the harder it is to see all of the relevant code at any one time, the more strain we put on our working memories. A naive strategy for reducing complexity is to reduce lines of code. But if we reduce the number of lines of code by introducing deeply nested function calls, the code becomes more complex not less as the number of lines decreases.
As a rough definition, let’s think of code complexity as ‘how difficult code is to reason about and work with.’ A good test of code complexity is how long it takes future you to remember what each line, or chunk, of code is for.
We’ll now explore some tools and heuristics for fighting complexity in our code.
24.5 On navigation
graph LR
A[Raw Data] --> B(Cleaning)
B --> C(Transformation)
C --> D(Visualisation)
D --> E(Modelling)
E --> F(Communicating Results)
E --> B(Cleaning)
Let’s go out on a limb and say that the data science workflow is never linear, you will always move back and forth between cleanin data, inspecting it, and modelling it. Structuring your projects and notebooks with this in mind will save many headaches.
Readme
For each project, add aREADME.md or README.Rmd, here you can outline what and who the project is for and guide people to notebooks, data artefacts, and any important resources. You may find it useful to maintain a to-do list here, or provide high-level findings - it’s really up to you, just keep your audience in mind.
Section Titles
Section titles help order your thoughts - when done well they let you see the big picture of your document. They will also help your collaborators to navigate and understand your document, and they’ll function as HTML headers in your rendered documents. When in the RStudio IDE the outline tab allows click-to-navigate with your section titles.
Tip
Set the toc-depth: in your quarto yaml to control how many degrees of nesting are shown in your rendered document’s table of contents.
Code chunks
You wrote the code in the chunk. So you know what it does, or at least you should. However, when rendering your document (which you should do regularly) it’s handy to have named chunks so that you know precisely which chunk is taking a long time to render, or has a problem. Furthermore, that 8-line pipe inside the chunk might not be as easy to understand at a glance in the future, and it certainly won’t be for your collaborators. It’s much easier to understand what a descriptively named chunk is doing than 8 piped function calls.
24.6 On comments
When following the literate programming paradigm, coding comments (# comment...) should be included in code chunks with echo = False unless you explicitly want your audience to see the code and the comments - save the markdown text for what your audience needs to see.
Generally code comments should be used sparingly, if you find yourself needing a lot of comments it’s a sign the code is too complex, consider re-factoring or abstracting (more on abstractions later).
24.7 On repeating yourself #1 - Variables
Storing code in multiple places tends to be a liability - if you want to make changes to that piece of code, you have to do it multiple times. More importantly than the time lost making the changes, you need to remember that the code has been duplicated and where all the copies are.
Without variables coding would be ‘nasty, brutish and short long.’. It’s difficult to find the Goldilocks zone between ‘more variables than I can possibly name’ and ‘YOLO the project title is typed out 36 times’.
Magrittr’s pipe operator (%>% or command + shift + m) can save you from having to create too many variables. It would be quite ugly if we had to always code like this:
mpg_horesepower_bar_chart <- ggplot(mtcars, aes(x = mpg, y = hp))
mpg_horesepower_bar_chart <- mpg_horesepower_bar_chart + geom_point()
mpg_horesepower_bar_chart <- mpg_horesepower_bar_chart + labs(title = "666 - Peaks & Pits - Xbox Horsepower vs Miles per Gallon")
mpg_horesepower_bar_chartInstead of this:
mtcars %>%
ggplot(aes(x = mpg, y = hp)) +
geom_point() +
labs(title = "666 - Peaks & Pits - Xbox Horsepower vs Miles per Gallon")Place strings you’ll use a lot in variables at the top of your notebook, and then use the paste function, rather than cmd + c, to use the contents of the variable where necessary. This way, when you need to change the title of the project you won’t have to mess around with cmd + f or manually change each title for every plot.
project_title <- "666 - Peaks & Pits - Xbox:"
mtcars %>%
ggplot(aes(x = mpg, y = hp)) +
geom_point() +
labs(title = paste0(project_title, " Horsepower vs Miles per Gallon"))Give your variables descriptive names and use your IDE’s tab completion to help you access long names.
Let’s say you’re creating a data frame that you’re not sure you’ll need. Assume you will need it and delete after if not, don’t fall into the trap of naming things poorly
tmp_df ❌
screen_name_counts ✅
24.8 On naming
The primary objects for which naming is important are variables, functions, code chunks, section titles, and files. Give each of these clear names which describe precisely what they do or why they are there.
24.9 On repeating yourself #2 - Abstractions
Do Not Repeat Yourself, so the adage goes. But some repetition is natural, desirable, and harmless whereas attempts to avoid all repetition can be the opposite. As a rule-of-thumb, if you write the same piece of code three times you should consider creating an abstraction.
Reasonable people disagree on the precise definition of ‘abstraction’ when it comes to coding & programming. For our needs, we’ll think about it as simplifying code by hiding some complexity. A good abstraction helps us to focus only on the important details, a bad abstraction hides important details from us.
The main tools for creating abstractions are:
- Functions
- Classes
- Modules
- Packages
We’ll focus on functions and packages.
On functions
Make them! There are lots of reasons to write your own functions and make your code more readable and re-usable. We can’t hope to cover them all here, but we want to impress their importance. Writing functions will help you think better about your code and understand it on a deeper level, as well as making it easier to read, understand and maintain.
For a more comprehensive resource, check in with the R4DS functions section
Also see the Tidyverse Design Guide for stellar advice on building functions for Tidyverse functions.
On anonymous functions
Functions are particularly useful when you want to use iterators like {purrr}’s map family of functions or base R’s apply family. Often these functions are one-time use only so it’s not worth giving them a name or defining them explicitly, in which case you can use anonymous functions.
Anonymous functions can be called in three main ways:
- Using
function()e.g.function(x) x + 2will add 2 to every input - Using the new anonymous function notation:
\x x + 2 - Using the formula notation e.g.
map(list, ~.x + 2)
You will see a mixture of these, with 3. being used more often in older code, and 2. in more recent code.
24.10 On packages
Depending on how many functions you’ve created, how likely you are to repeat the analysis, and how generalisable the elements of your code are, it may be time to create a package.
At first building a package is likely to seem overwhelming and something that ‘other people do’. However, in reality the time it takes to create a package reduces rapidly the more you create them. And the benefits for sharing your code with others are considerable. Eventually you’ll be able to spin up a new package for personal use in a matter of minutes, over time it will become clear which packages should be developed, left behind, or merged into an existing SAMY package.
Visit the Package Development document for practical tips and guidelines for developing R packages
see also: Package Resources
24.11 On namespaces and function conflicts
R manages functions via namespaces. Depending on the order that you import your packages, you may find a function doesn’t behave as expected. For example, the {stats} package has a filter() function, but so does {dplyr}. By default R will use the most recently-imported package’s namespace to avoid any conflicts, so filter() will now refer to {dplyr}’s implementation.
If you’re experiencing weirdness with a function, you may want to restart your R session, change the order of your imports to prevent the same weirdness occurring again. However, a more straightforward approach is to use the package:: notation to explicitly refer to the function you intended to use e.g. dplyr::filter() will avoid any potential conflicts and confusion.
24.12 On version control
By default your projects should be stored on Google Drive inside the “data_science_project_work” folder, in the event of disaster (or minor inconvenience) this means your code and data artefacts should be backed up. However, it’s still advisable to use a version control system like git - using branches to explore different avenues, or re-factor your code, can be a real headache preventer and efficiency gain.
Aim to commit your code multiple times per day, push to a remote branch (not necessarily main or master) once a day and merge + pull request when a large chunk of work has been finished. Keep your work code and projects in a private repository, add .Rhistory to .gitignore and make sure API keys are stored securely, i.e. not in scripts and notebooks.
24.13 On Managing Dependencies
Applying the Anna Karenina principle to virtual environments:
“All happy virtual environments are alike; each unhappy virtual environment is unhappy in its own way”
R
The R ecosystem - led by CRAN and posit (formerly RStudio) - does a great job in managing package-level dependencies. It’s rare to end up in dependency hell R. However, there is still scope for ‘works on my machine’ when working with collaborators who have different versions of a package, e.g. person 1 upgrades their {dplyr} version before person 2, and now that .by argument person 1 has used is breaking code on person 2’s machine.
To avoid this, we advise using something like the {renv} package to manage package versions.
On using renv collaboratively
renv helps us keep track of package & R versions, which makes deployment 10x easier than without it. However, it can get tricky if we’re using renv in different ways.
Start a renv project off withrenv::init(), this will essentially remove all of your packages. You could choose to take your current packages with you, but it’s not advised. These packages are linked to your RStudio project when using RStudio, which means other RStudio projects will have your current packages if they’re not themselves using renv.
renv::init() creates a renv lockfile, you’ll need to keep this up to date as you work through the project - especially important if collaborating with other people on a project that uses renv. Once installed inside your local project, you can add single packages to the lockfile by renv::record("package_name"). This is preferable to adding a bunch of packages at a time with renv::snapshot() particularly when collaborating. Generally it will be better to give one person control of the lockfile and to communicate about adding packages as and when.
If you’re working in a Quarto Doc or an RMarkdownfile to develop things that don’t need to pushed to the repo, you can create a .renvignore file like .Rbuildignore, .gitignore etc. and add the folder where the markdowns sit to make sure renv doesn’t try to sync itself with the packages you’re experimenting with.
At any time you can check your environment is still synced with renv::status(), if your project is out of sync, you may want to renv::clean(), if you’ve got a bunch of packages that are like this:
The following package(s) are in an inconsistent state:
package installed recorded used
backports y y n
blob y y n
broom y y n
callr y y n
cellranger y y n
Then you’ll need to renv::clean(actions = "unused.packages"), which should get you in working order. There’s a lot more to {renv} when collaborating but these steps will do a lot to keep your environment in sync and allow collaborators to use your code.
Python
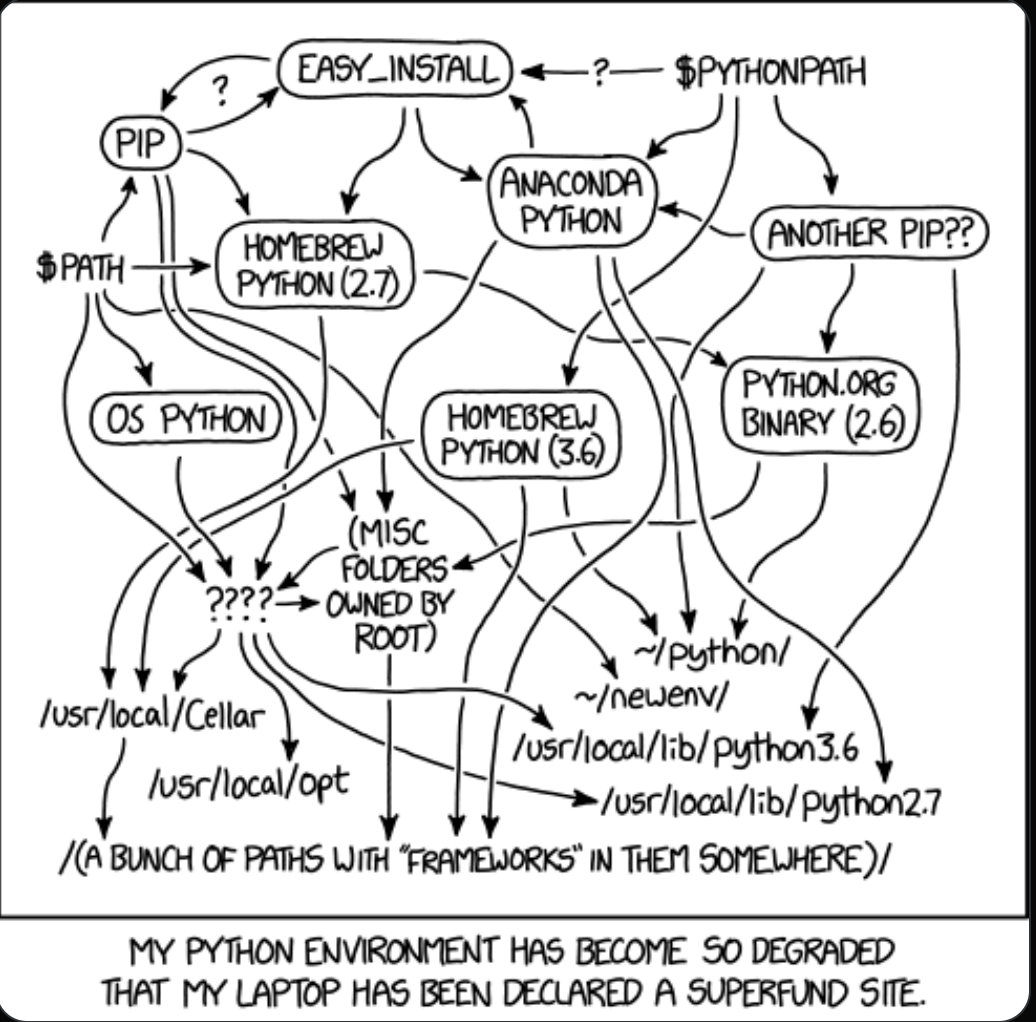
Unlike R, it’s pretty easy to get into deep, deep trouble when working with Python environments. We advise using miniconda, keeping your base environment completely free of packages, and creating virtual environments for projects or large, but commonly-used and important packages like torch.
Tip
Just remember to activate the correct environment every time you need to install a package!
24.14 On LLM-generated code
GitHub Copilot, ChatGPT, Claude and other LLM-based code generators can be extremely useful, but they are a double-edged sword and should be used responsibly. If you find yourself relying on code you don’t understand, or couldn’t re-build yourself, you’re going to run in to trouble somewhere down the line. You have the time and space to learn things deeply here, so do read the docs, do reference textbooks, and do ask for help internally before relying on LLM-generated code which often looks right but is outdated or subtly incorrect/buggy.
Tip
You’re here because you can problem solve and pick up new skills when you need them - don’t be afraid to spend extra time understanding a concept or a library.
24.15 Great Coding Resources
24.16 Exercises
In your own words, summarise what makes an analysis reproducible.
Write a line in favour and against the claim ‘Code is an asset not a liability.’
Set up a private github repo on a project inside data_science_project_work/internal_projects and create a new branch then commit, push and pull request a change.
Add your own best practices to this document!