12 Data Labelling and Collection
Before even thinking about collecting data, make sure that you have:
- Understood the problem and defined the research question
- Established the task needs machine learning
12.1 Setting Goals
So you’re sure you need machine learning and you’ve understood the research question. Now is the time to establish your modelling goals, as your data labelling and collection strategy should flow directly from these goals.
Answer the following questions to help you establish your goals:
From your answers to these questions, you could establish goals like:
- Accuracy must be 80% - or 1/5 error rate
- False positives & negatives are equally important, so we want precision and recall to be within 2% of each other for each class.
Establishing these goals will help keep you on track, and inform you when it’s time to stop collecting more data.
Note
Information on our recommended stack for labelling can be found in the Data Labelling Stack document.
12.2 Achieving our Goals
Something that we cannot stress enough, is that data is the single most important factor in any Machine Learning project. We need to find a high enough quantity of high quality data to achieve our modelling goals\(^{\text{tm}}\).
This raises two questions:
- How much data is enough?
- What is quality when it comes to data?
There is a circularity to the answer of both questions. Enough data is the amount of data that it takes you to achieve your modelling goals1. Quality data is data that helps you achieve your modelling goals2. Despite this circularity, we put evaluations in place that tell us whether our changes are positively impacting our ability to achieve our modelling goals, or not.
Quantity
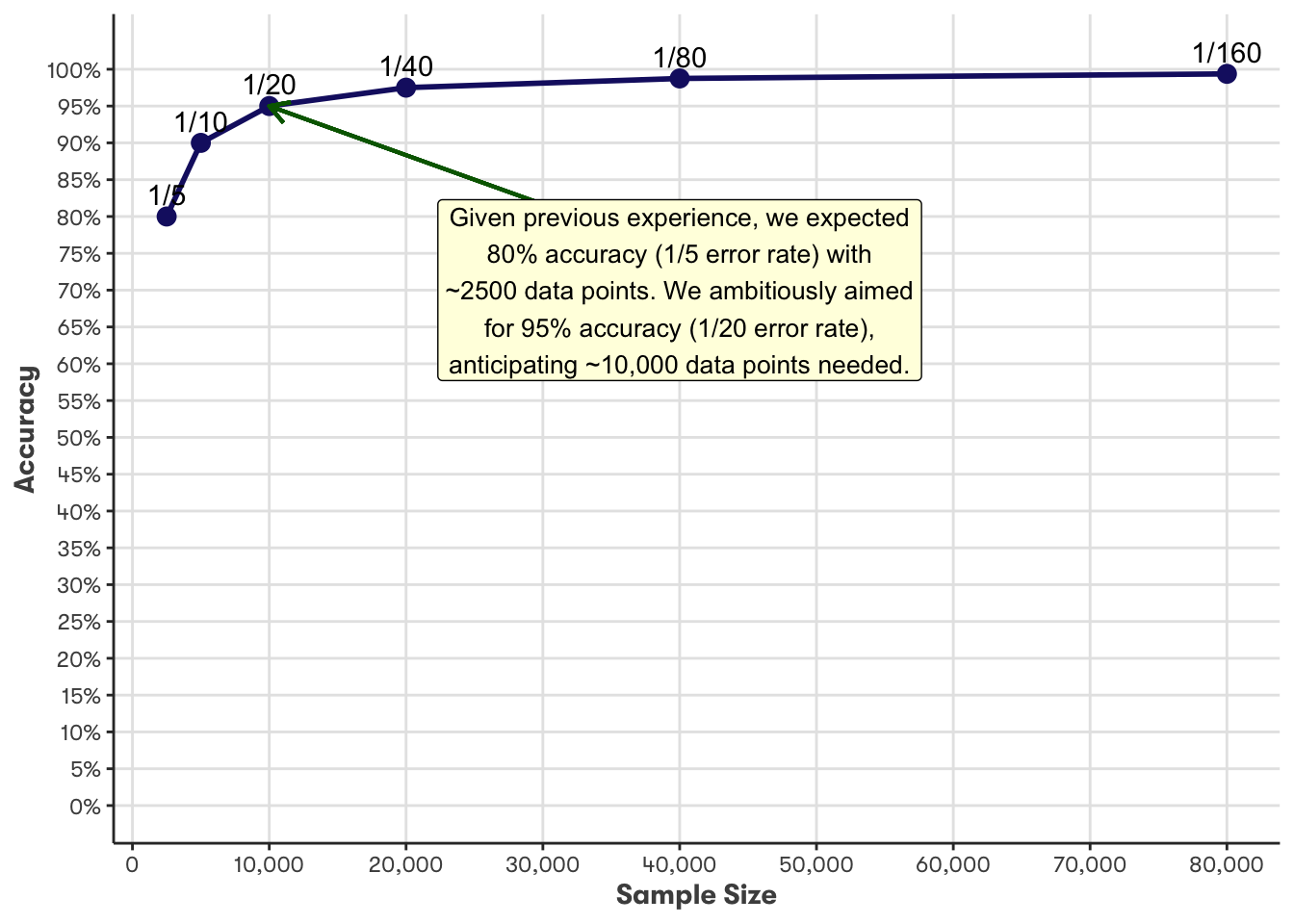
Thankfully, for text classification tasks that involve foundational models & Transfer Learning, the models already understand language so we do not have to teach them to understand it. This would require a lot of data. For our purposes, we tend to need \(1,000 \lesssim x \lesssim 10,000\) samples to get the required performance.
Another rule of thumb is that if we want to halve the error rate, we need to double the sample size. Clearly the required sample size grows exponentially as we get closer to 100% accuracy, so we have to balance model performance versus allocated resources.
Warning
Update: more research suggests we will often need 4-5x as much data to halve errors.
Clearly, if we need 2x (or more) as much data to halve errors, the amount of data we need is going to grow very quickly. As you progress through the project, keep in mind that any information you can acquire about this relationship is valuable. One strategy for understanding the relationship is to train a model on progressively larger samples. Record the accuracy for [100, 200, 500, 1000, 2000] samples and visualise, what effect is increasing sample size having on accuracy? Extrapolate the trend and you have a hypothesis for a scaling law which you can test.
More rows \(\neq\) more data
It’s easy to conflate the number of rows, or samples, with the quantity of data. 1,000,000 identical mentions contain the same amount of data as just 1 of those mentions. Accidentally filling your dataset with a load of duplicates or near duplicates will mislead you into thinking you have more data than you do in fact have. This in turn may mislead you on how well the scaling laws are holding - i.e. you are adding ‘data’ but not seeing increases in your metrics.
Class Balance
If your classification task is binary - it has two possible labels - you should aim for an approximately 50/50 split. If you have 3 labels aim for a 33% split, irrespective of the distribution of the dataset that you will eventually be classifying. This is a very important rule of thumb that you should only break when you really know what you are doing. Even if you have a reasonable expectation that the true probability distribution will skew in one label or another’s favour, balancing the number of labels will make the learning 3 process smoother and more robust. Smooth and robust learning processes prevent many unnecessary headaches.
Quality
Dovetailing with quantity, we need quality data. How do we define quality? Quality data is data that improves your model. It’s somewhat circular but that’s really all there is to it.
Quality data will tend to be varied - combined it will cover the full range of ‘things’ the model needs to perform the task at hand, e.g. it covers the range of vocabulary the model will encounter when deployed, and it covers the types of syntactic sequence, or structure, that lead to one classification over another.
Syntactic Sequences and Pattern Recognition
As humans we can make reasonable inferences about texts very quickly. For example, it takes us very little time (essentially it’s instant) to understand what a sentence in our native language is about, what intention the sentence was written with and a host of other things. We can do this because we have extreme capacity for pattern recognition.
When classifying and analysing texts, we pay attention to details like word order, or punctuation, to infer meaning, consider a canonical example:
- “Let’s eat, John.”
- “Let’s eat John.”
We can do this because we have learnt the rules associated with commas. Most models for text classification would not, without further instruction, know the difference between 1. and 2. If this difference is important for our task, then we need to go out and find instances of this pattern to teach the model.
We should be able to determine whether a particular difference is important according to how frequently we find it in our training data when labelling.
If, once trained, the model is going to receive inputs with emojis, special characters, numbers, punctuation etc. then it should have examples of these in both the positive (spam) and negative (not spam) labels. This is very important. If the model only has emojis in the positive labels, it will learn that emoji = spam. This is undesirable.
Staying within Distribution
One way of understanding modern machine learning models is that they compress patterns in their training data 4. Another way of thinking about machine learning models is to think of them as programs, and sub-programs. These views are complementary, and together they imply one of the most important challenges we have to confront when building Machine Learning models, namely, that they do not generalise well.
Given this, we should aim to train our model on the type of data that it will encounter at test time (when you deploy the model and use it for inference on new data), and we should expect our model to perform worse on data in proportion to how different the data is to our training data.
Iteration
As with everything in Data Science, the process of acquiring data and labelling data is fundamentally iterative. At each step of the modelling process you will uncover some new fact about your data, or some problem in your data, which sends you back to the beginning of the process. You then collect more data to solve this problem, and test the effect this data has on your model.
This process will require looking at a lot of data - you can think of data here as your input documents, your model’s predictions, your
How do you know when you’re done?
You have exhausted the available time, you’re out of ideas for how to improve your model, your model is performing at, or above, the targets you set out to achieve.