10 Downstream flourishes (Step 7)
10.1 BERTopic to find high-level peaks and pits
Now we have an extremely refined set of posts classified as either peak or pits. The next step is to identify what these moments actually relate to (i.e. identify the topics of these moments through statistical methods).
To do this, we employ topic modelling via BERTopic to identifying high-level topics that emerge within the peak and pit conversation. This is done separately for each product and peak/pit dataset (i.e. there will be one BERTopic model for product A peaks, another BERTopic model for product A pits, an additional BERTopic model for product B peaks etc).
We implement BERTopic using the R package BertopicR. As there is already good documentation on BertopicR this section will not go into any technical detail in regards to implementation.
10.2 Brand Love Emotion States
As outlined in the introduction, Microsoft are pushing for peak and pit posts to be linked to their “Brand Love” framework:
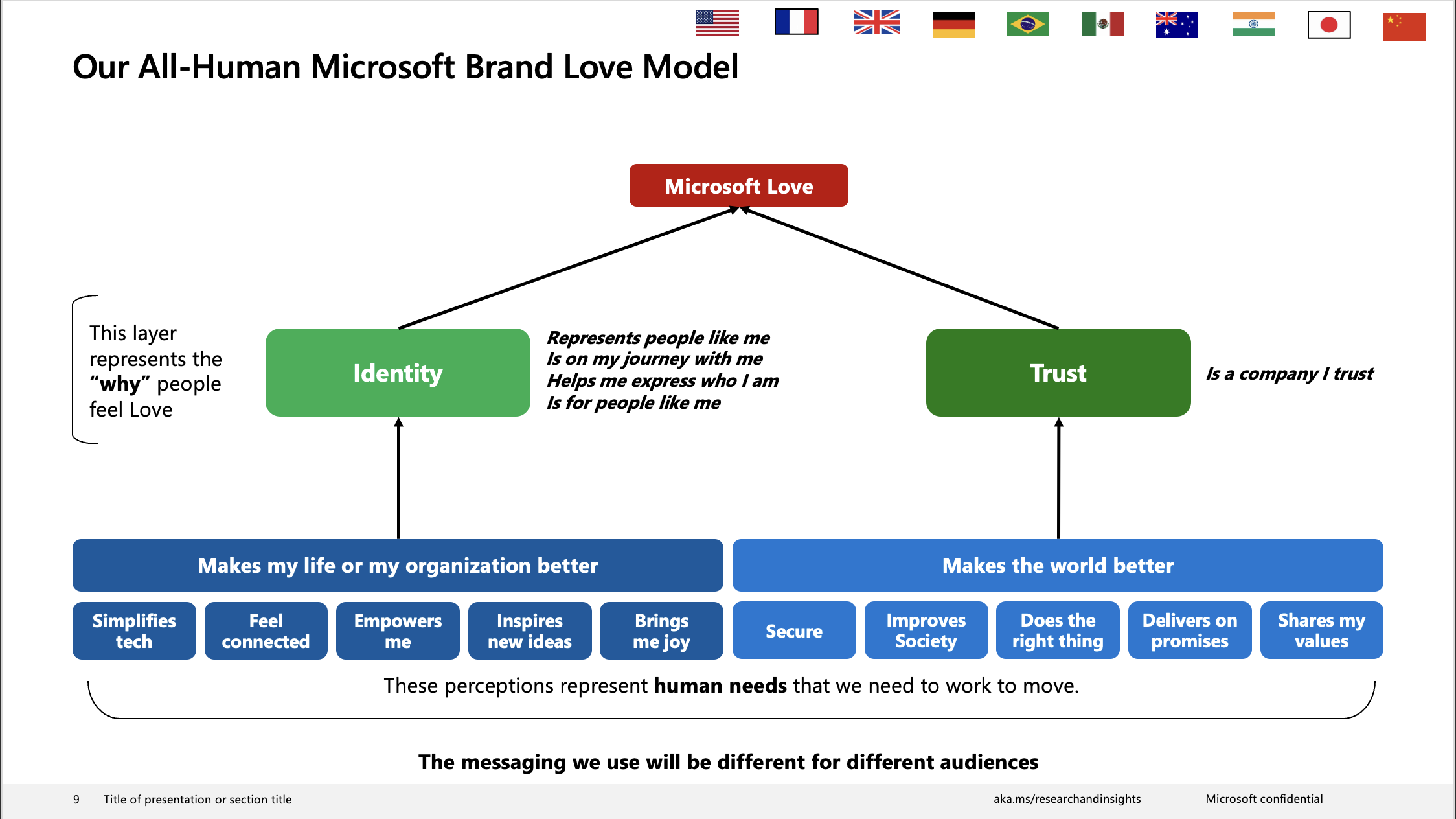
Figure 3.1: Microsoft Brand Love Framework from the powerpoint ‘All Human Emotionality References Deck All Audiences’ … catchy
This framework sees the concept of “Brand Love” being split into two distinct groups of “Emotion States”, the first group contributing towards how a product or brand makes ones life better, and includes the concepts of:
- Simplifying tech
- Feeling connected
- Feeling empowered
- Being inspired
- Feeling joy
The second group contributes to a more holistic overview of the product or brand. Microsoft thinks of this as “making the world better” and includes concepts of:
- Security
- Improving society
- Doing the right thing
- Delivering on promises
- Sharing values with the user
These are all broad concepts that Microsoft will tweak based on their specific marketing purpose (i.e. different audiences), but we need to find the core make up of each Emotion State.
We have not yet built out a model or workflow for all 10 Emotion State classifications. But currently our implementation for the “making my life better” concepts involves using custom GPT-3.5 prompts for each of the emotion states. Despite the outcome of the analysis being multilabel, we achieve this by performing many binary classification models (i.e. “does the post contain the concept of simplifying tech” - “Yes” or “No”). Whilst this is not the most streamlined approach, initial trials showed trying true multilabel classification with a long and detailed prompt overwhelmed the model and produced incorrect classifications (determined by human evaluation).
This section will continue to be updated during the current project as we iterate on our approach to classify all 10 emotion states.